tl;dr: If you follow this blog you’ve seen me experiment with iframe-based citations; this post is about open-sourcing that tooling. Skip to demo, implementation tutorial, and GitHub link.
Knowledge tooling is happily becoming a hot topic again. With this trend is coming revived interest in Xanadu, bi-directional hyperlinking, knowledge databases, visualizing knowledge graphs, and so on. At this moment, I see most of the emphasis being put on tooling for the research side, with Notion, Workflowy, and the new and hyped Roam Research leading the way.
Where I see less focus is the writing part of the knowledge production process, where older apps like Scrivener are still the thing to beat. And almost nobody at all is working on the reader’s experience. As a blogger who largely caters to a wide audience, I’m especially interested in these areas.
Written information is largely still presented as a single document, and writing tools are geared toward the production of long pages. But before I say what’s wrong with this, let me sing the praises of documents for a moment.
People often get carried away when they discover the original vision of hypertext, which involves a network of documents, portions of which are “transcluded” (included via hypertext) into one another. The implication is that readers could follow any reference and see the source material—and granted, this would be transformative. However, there’s a limit to the effectiveness of the knowledge network as a reading experience. “Hypertext books,” online books which are made up of an abundance of interlinked HTML pages, are mostly unpopular. The failure of this experiment is, in my opinion, very revealing.
 Tinderbox map of a portion of David Kolb’s hypertext book Sprawling Places
Tinderbox map of a portion of David Kolb’s hypertext book Sprawling Places
Knowledge is not an accumulation of facts, nor is it even a set of facts and their relations. Facts are only rendered meaningful within narratives, and the single-page document is a format very conducive to narrative structure. The hypertext books that have gained popularity (I’m thinking here of Meaningness.com) have largely conformed to this in two ways: 1) there is an intended reading order, and 2) the longer essays within the project do most of the heavy lifting in terms of imparting the author’s perspective to readers.
On the other hand, the notion of the “document” that is intrinsic to web development today is overdetermined by the legacy of print media. The web document is a static, finished artifact that does not bring in dynamic data. This is strange because it lives on a medium that is alive, networked, and dynamic, a medium which we increasingly understand more as a space than a thing.
For example, consider how silly it is to include MLA-style citations at the bottom of a text when we have the vast capabilities of linked documents on the web. Why should the reader have to read every citation or trust that an author is not taking a citation out of context, when hyperlinks are available?
This all suggests that a compromise must be struck between the coherence of a text and the new opportunities for knowledge work afforded by the fundamental capabilities of the medium: the internet’s connectivity, the screen’s frame rate.
My own blogging is one context in which I’ve seen this tension play out, and have been working to explore ways of making my texts richer. A lot of the ideas I talk about in various pieces of writing are connected to one another. When I publish an essay, I’m not done with it. The ideas live on and get renewed, reused, and recycled in later works. Some sentences contain definitions that are core to my mental models, and there are whole paragraphs that might be useful out of context. I’m building my knowledge network in mind maps and behind various SaaS APIs, but how can I publicly show my thinking to be part a cohesive worldview?
Normally people solve this by simply block quoting themselves, but this is a waste of an opportunity. The indented block quote is a print medium invention almost as old as typesetting. The block quote is plaintext, it is not actually linked to the original text or its context.
I’ve been experimenting with one idea for a solution, and if you’ve read the last couple blog posts you’ll have seen it there. My stab at an answer is an iframe which shows the quote within its original context and gives a hint at its surroundings. Effectively, it’s a transclusion within my own blog. I’m currently satisfied with what I have as a v1, and am interested to see if others find it useful, so I’m open sourcing it here and including a tutorial.
Open Transclude
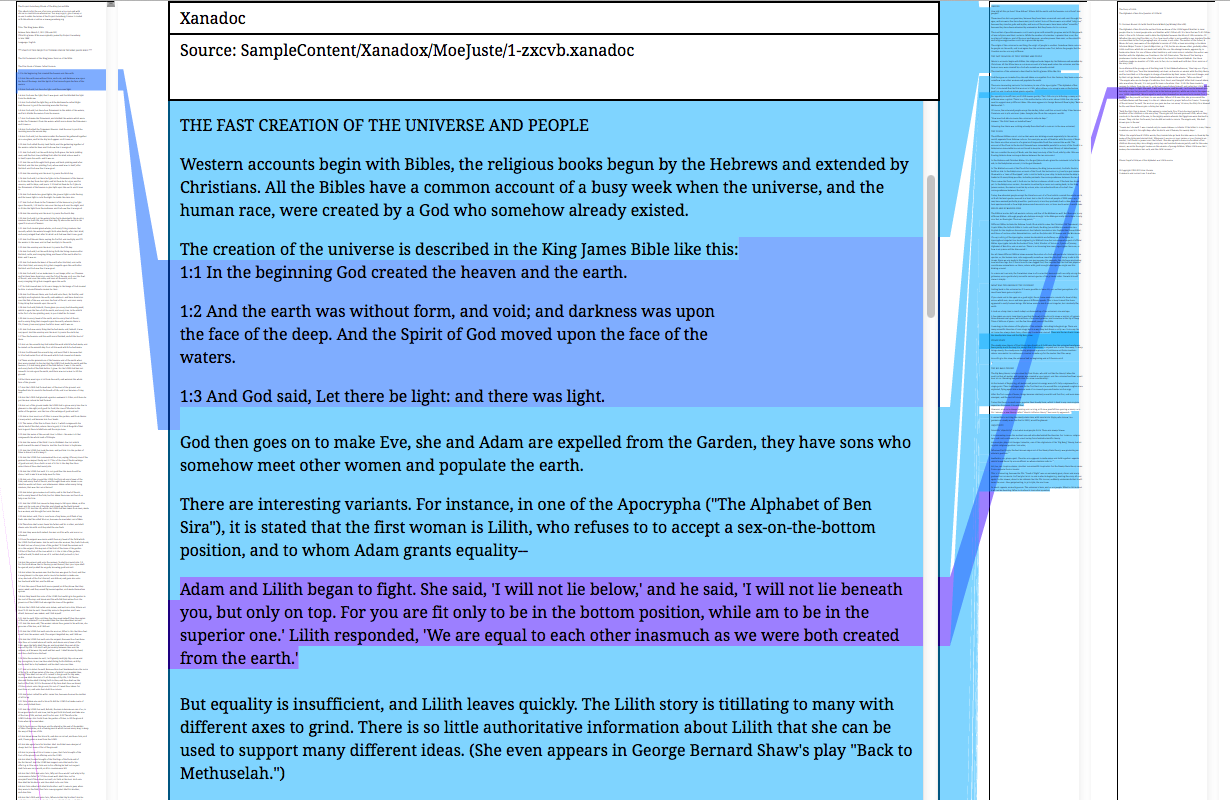
Open Transclude is a UX pattern, a spec for networked writing within your own blog. Here’s how it looks:
What you are looking at is an scroll-locked iframe that links to a quote I picked out of my blog post “Notes on Comparative Psychology.” You can use Open Transclude anywhere you can drop an <a> tag on your own site.
Open Transclude:
- Works anywhere on your own domain
- Compatible with most static site generators / templating engines
- 12 lines of HTML, 80 lines of SCSS, 22 lines of JS (4.5 kb total)
- Has 0 dependencies — this is native web technology
Open Transclude is extremely simple, and the heaviest part of the code is the CSS, which you can simplify at your whim. That’s why I am referring to it as a UX pattern. This is not a protocol. The code is really a commodity. What’s interesting about it is the idea and the design, and this is just one viable implementation! Feel free to adapt it however you like.
The principal improvement over a block quotation is sense of context.
Over on GitHub you’ll find the reference implementation for Jekyll. Below is a tutorial for implementing it yourself, by way of also explaining some of the technical design decisions.
Implementation Recipe
Here’s what you need to do to get Open Transclude up and running.
- Create an anchor tag in the blog post where you want to cite yourself.
- Create the HTML for the reusable transclusion component.
- Call the portal into any document and passing it Jekyll variables.
- A small piece of Javascript which populates your transclusion into the document.
- Create the SCSS file with the component’s styles.
1. Create the anchor tag where you want to cite yourself
To quote yourself, you’ll need to create an <a> anchor tag in the markdown file for the post you want to quote. If you wish to highlight a specific piece of text, instead create a <span></span> around the section you want to quote. Note that this can only be on your own website—it doesn’t work cross domain.
Here’s what it looks like for the example iframe above.
It will, for one thing, become newly conscious of itself, and, to the degree that it is, **it will tend to undermine its own experiential integrity**" (emphasis mine).
<span name="mainstream-magic">Ironically, psychology remains one of the closest things we have to a mainstream magic or a mystical art today. Not only is it plainly the direct descendent of medieval magic, as I learned when I read Ioan Coulianou's *Eros and Magic in the Renaissance* earlier this year. **It is a theory of the self that is phenomenologically accurate, objectively wrong, and is based on magical thinking even as it deconstructs itself**.</span> Some magical thinking processes that happen in psychotherapy, such as [transference to the psychologist](https://en.wikipedia.org/wiki/Transference#Transference_and_countertransference_during_psychotherapy), are even intended to stay unmentioned to the patient in order to be utilized most effectively by the therapist!2. Create your iframe component
This is most useful as a standardized component which can be used across the site, so we are going to take advantage of Jekyll’s templating features. Jekyll and other static site generators like Kirby and Zola support HTML “partials” or “includes” so that you can create reusable components.
In your /_scss or /_sass folder make a new file, portal.scss. I called it “portal” because it’s shorter than “transclusion” and less prone to spelling errors.
Here’s our component:
<div class="portal-container">
<div class="portal-head">
<div class="portal-backlink" >
<div class="portal-title">From <span class="portal-text-title">{{ include.title }}</span></div>
<a href="{{ include.link }}" class="portal-arrow">Go to text <span class="right-arrow">→</span></a>
</div>
</div>
<div id="portal-parent-{{include.anchor}}" class="portal-parent">
<div class="portal-parent-fader-top"></div>
<div class="portal-parent-fader-bottom"></div>
<!-- We'll use Javascript to populate the iframe right here -->
</div>
</div>You’ll notice immediately that the iframe isn’t there yet. Like I mentioned above, we’re going to be populating it with Javascript.
You’ll also see that in various places we’re using {{ include.___}}. A cool thing about Jekyll includes its that it’s possible to define variables and pass them to our include, so we can create reusable components across our site. Dave Rupert has a nice blog post about this called if you want to see more advanced examples!
3. Calling the component
Anytime you want to pull this component into a blog post, all you have to do is include it in the markdown of another blog post, like this:
{% include portal.html title="Notes On Comparative Psychology" link="/entries/notes-on-comparative-psychology/#mainstream-magic" anchor="emotional-deficit" %} When you include it, you’ll need to pass in those three variables - title, link, and anchor, that fill in the includes above. If you’re following along now and making a build in Jekyll, you’ll see an empty, unstyled component with the link. So good so far!
4. Populating with Javascript
This is a good time to address why we need Javascript. Web developers reading this are probably asking why we don’t simply put the full /link#with-anchor into the iframe src and be done with it. Unfortunately, there is a bug on several browsers that makes the parent document jump down to the iframe when the page loads. Thus we need to load the iframe into our component afterwards.
Inside portal.html make a new <script> tag and put the following inside. Because it’s inside our portal component, we can actually pass our include variables right into the Javascript! Just make sure there are quotes around them.
<script>
function linkFunction(link) {
// take the link we passed in and split it into the base URL and the anchor tag
var baseSlug = link.split('#')[0];
var atag = link.split('#')[1];
// we need to know the parent element so we can append it
const parent = document.getElementById('itxt-body-{{include.anchor}}');
// now let's create the iframe, set its attributes and append it to our parent element
const frame = document.createElement('iframe');
parent.appendChild(frame);
frame.setAttribute("id", atag);
frame.setAttribute("class", "portal-iframe");
frame.setAttribute("src", baseSlug);
frame.setAttribute("scrolling", "no");
// finally, we'll create the iframe
setTimeout(function(){
const innerDoc = frame.contentDocument || frame.contentWindow.document;
= innerDoc.getElementsByName(atag)[0]; // find the corresponding span or anchor tag
// set text decoration on the quoted element
anchor.setAttribute('class', 'portal-quote-text');
// get position of the anchor relative to the start scroll position
var offset = anchor.getBoundingClientRect().top;
// NOTE: replace this with your theme's default spacing unit
var spacing = 25
// checks to see if you wanted to override the spacing
// if text is highlighted, center it
if (anchor.innerHTML && anchor.innerHTML !== "") {
offset = offset - (spacing * 4);
};
// jump scroll the iframe content to the anchor
frame.contentWindow.scrollBy(0, offset);
}, 1000);
};
linkFunction("{{include.link}}");
function linkFunction(link) {
var baseSlug = link.split('#')[0]; // get the base slug
var atag = link.split('#')[1]; // get the hash
var parent = document.getElementById('itxt-body-{{include.anchor}}');
const frame = document.createElement('iframe');
parent.appendChild(frame);
frame.setAttribute("id", atag);
frame.setAttribute("class", "portal-iframe");
frame.setAttribute("src", baseSlug);
frame.setAttribute("scrolling", "no");
setTimeout(function(){
const innerDoc = frame.contentDocument || frame.contentWindow.document;
anchor = innerDoc.getElementsByName(atag)[0]; // find the corresponding anchor tag
// set text decoration on anchor
anchor.setAttribute('class', 'portal-quote-text');
// get position of the anchor relative to the start scroll position
var offset = anchor.getBoundingClientRect().top;
// NOTE: replace this with your theme's default spacing unit
var spacing = 25
// checks to see if you wanted to override the spacing
// if text is highlighted, center it
if (anchor.innerHTML && anchor.innerHTML !== "") {
offset = offset - (spacing * 4);
};
// jump scroll the iframe content to the anchor
frame.contentWindow.scrollBy(0, offset);
}, 1000);
};
</script>Note: in order to debug this more easily using your browser’s debugging tools, you might want to also have a portal.js file and link to it using <script src="/portal.js"></script>. If you do this, you won’t be able to use includes in JS—you’ll need to specify the links exactly instead.
Let’s talk about what this function is doing. Mainly, it’s:
- Calling function “linkFunction” and passing in link that we set in part 2.
- Creating an iframe with that link and appending it to its proper parent element.
- Calculating the distance between the top of the document inside the iframe and the anchor or span tag inside it, then scrolling that distance. (Remember, we have to do this because if we loaded the link directly it would scroll the whole parent document.)
You might be wondering: why are we also passing a variable to the class of our iframe’s parent element? itxt-body- looks kind of funky.
The reason for this is to support multiple transclusions per post. Every time you include this piece of HTML, this function is getting called, so we need to make sure that it’s specifying the right parent. If you don’t specify it here, Javascript will just find the first itxt-body in the post and populate it with every iframe you’re trying to load. If you scroll back up, you’ll see that it matches portal.html exactly.
This function will append a new iframe to the portal-parent div, set scrolling to no, and give it a class so we can style the thing.
<iframe scrolling="no" src="/posts/notes-on-comparative-psychology/#mainstream-magic"></iframe>Styling
At this point, you should just head over to GitHub, grab the included portal.scss file, and style it how you want. I’m just going to leave a few tips here.
Most browsers automatically style iframes, so you’ll want to clear that out.
iframe{
border: none;
}The most interesting design element here is the scrim that makes it look like the text is fading out at the top and bottom of the iframe. This is actually accomplished with two absolutely positioned gradients:
.portal-parent{
overflow:hidden;
position: relative;
width:100%;
box-sizing: border-box;
.portal-parent-fader-top{
position: absolute;
width: 100%;
margin-left: 0px;
height: 36px;
background-image: linear-gradient(rgba(255,255,255,1), rgba(255,255,255,0));
z-index: 50;
}
.portal-parent-fader-bottom{
position: absolute;
width: 100%;
bottom: 8px;
margin-left: 0px;
height: 36px;
background-image: linear-gradient(rgba(255,255,255,0), rgba(255,255,255,1));
z-index: 50;
}
.portal-parent-text{
padding:$base-line-height / 2;
color: #5C6D73;
z-index: 40;
}
.portal-iframe{
width:100%;
height:400px;
}
}Again, this isn’t the full SCSS. You can get that from the GitHub!
Improvement Ideas and Addendum
One thing I’ve learned is never to expect that code works out of the box. So if it doesn’t, don’t get mad at me! I’ve implemented this twice now—once on my own site, and once on the out-of-the-box Jekyll build you can find on GitHub—so I know it works.
I’d love to see this adapted for other static site generators. In addition, I have a few ideas for improvements that better developers than I can figure out. I can’t pay anything, but you’ll win honor and glory.
- Enable bounded scrolling. Ideally, readers should be able to explore the context that is being quoted, but not go wild and scroll to the top of the window. Being able to scroll up and down a few hundred pixels would be super powerful.
- Quote highlighting. Especially if limited scrolling is enabled, it would be cool to automatically highlight the quoted section. Update 3/5/2020: this has been implemented by Twitter user @in_mcdonalds! Thanks so much!
- Variable height based on length of quoted segment. This and above suggestion would probably work by specifying the start and end of a quoted segment.
- Gatsby implementation.
- PHP / Kirby implementation.
- Django implementation.
- Efficiency improvements. If someone can figure out how to do this with less code, by all means make a pull request.
That’s the whole thing. It’s pretty straightforward, but I think it’s cool and a more web-native way of doing block quotes. If you implement it on your own site, send it my way, I’d love to feature your implementation on this page.
I’ll leave you with a few final thoughts on projects like this one.
I have no idea whether this thing will be adopted or not, but in principle, there is a great deal of value to be generated by working on open designs and UX patterns. To paraphrase the LOT2046 code of practice, not every line of code or feature deserves its own corporation. If we insist on contorting every good idea to fit into a corporate medium, we will never see the future we want come to fruition. It’s that simple. I’d like to see more designers working for the public and positioning ideas that way.
The web is still a very young medium, and it has been influenced more than anything else by print media design. There is so much more that can be done with text on a screen than is being done today. Citations, drawing, chat, speech-to-text. There are opportunities everywhere, and the bar is low! If we are serious about unlocking the value of knowledge we should consider how to improve every part of the knowledge production stack, and that includes reading. As Laurel Schwulst says: “Imaginative functionality is important, even if it’s only a trace of what was, as it’s still a sketch for a more ideal world.”